Codificación de caracteres en python 2.X

Cuando mis alumnos se enfrentan a realizar su proyecto de fin de curso creando una aplicación web en python casi siempre se encuentran con la problemática de las diferentes codificaciones con las que trabaja python. Normalmente trabajan con variables locales de tipo cadena que están codificada en utf-8, sin embargo cuando leen datos que provienen de una API web se puede dar el caso que la codificación sea unicode. En estos casos siempre les cuesta mucho trabajo tratar con los caracteres no ingleses codificados de diferente forma.
En estos días estoy desarrollando una aplicación web y me estoy encontrado con el mismo problema. Por lo tanto el objetivo de escribir esta entrada en el blog es hacer un resumen de cómo python gestiona las diferentes codificaciones y que sirva como material de apoyo para la realización de los proyectos de mis alumnos.
Codificaciones de caracteres
Entendemos un carácter como el componente más pequeño que puede formar un texto. Aunque muchos caracteres son iguales en los distintos idiomas, hay caracteres específicos para cada alfabeto, que tienen grafías diferentes. Evidentemente para guardar en un ordenador cada uno de los caracteres es necesario asignar a cada uno un número que lo identifique, y dependiendo del sistema que utilicemos para asignar estos “códigos” nacen las distintas codificaciones de caracteres.
En los principios de la informática los ordenadores se diseñaron para utilizar sólo caracteres ingleses, por lo tanto se creó una codificación de caracteres, llamada ascii (American Standard Code for Information Interchange) que utiliza 7 bits para codificar los 128 caracteres necesarios en el alfabeto inglés. Por lo tanto con esta codificación, es imposible representar caracteres específicos de otros alfabetos, como por ejemplo, los caracteres acentuados.
Posteriormente se extendió esta codificación para incluir caracteres no ingleses. Al utilizar 8 bits se pueden representar 256 caracteres. De esta forma para codificar el alfabeto latino aparece la codificación ISO-8859-1 o Latín 1. Puedes ver las tablas de estos códigos en la siguiente tabla.
Unicode
En el momento en que la informática evolucionó y los ordenadores se interconectaron, se demostró que los códigos anteriores son insuficientes, al existir en el mundo muchos idiomas con alfabetos y grafías diferentes. Por lo tanto se crea la codificación unicode que nos permite representar todos los caracteres de todos los alfabetos del mundo, en realidad permite representar más de un millón de caracteres, ya que utiliza 32 bits para su representación, pero en la realidad sólo se definen unos 110.000 caracteres.
Por lo tanto esa es una de sus limitaciones, que utiliza muchos bytes para la representación, cuando normalmente vamos a utilizar un conjunto pequeños de caracteres. De este modo, aunque existen códigos que utilizan 32 bits (utf-32) y que utilizan 16 bits (utf-16) el sistema de codificación que más se utiliza es el utf-8. Aquí tienes un enlace a la tabla de códigos unicode.
utf-8
UTF-8 es un sistema de codificación de longitud variable para Unicode. Esto significa que los caracteres pueden utilizar diferente número de bytes. Para los caracteres ASCII utiliza un único byte por carácter. De hecho, utiliza exactamente los mismos bytes que ASCII por lo que los 128 primeros caracteres son indistinguibles. Los caracteres “latinos extendidos” como la ñ o la ö utilizan dos bytes. Los caracteres chinos utilizan tres bytes, y los caracteres más “raros” utilizan cuatro. Por lo tanto la representación de los caracteres españoles que no son ASCII:
| char | ANSI# | Unicode | UTF-8 | Latin 1 | nombre |
|---|---|---|---|---|---|
| ¡ | 161 | u’\xa1’ | \xc2\xa1 | \xa1 | inverted exclamation mark |
| ¿ | 191 | u’\xbf’ | \xc2\xbf | \xbf | inverted question mark |
| Á | 193 | u’\xc1’ | \xc3\x81 | \xc1 | Latin capital a with acute |
| É | 201 | u’\xc9’ | \xc3\x89 | \xc9 | Latin capital e with acute |
| Í | 205 | u’\xcd’ | \xc3\x8d | \xcd | Latin capital i with acute |
| Ñ | 209 | u’\xd1’ | \xc3\x91 | \xd1 | Latin capital n with tilde |
| Ó | 191 | u’\xbf’ | \xc3\x93 | \xbf | Latin capital o with acute |
| Ú | 218 | u’\xda’ | \xc3\x9a | \xda | Latin capital u with acute |
| Ü | 220 | u’\xdc’ | \xc3\x9c | \xdc | Latin capital u with diaeresis |
| á | 225 | u’\xe1’ | \xc3\xa1 | \xe1 | Latin small a with acute |
| é | 233 | u’\xe9’ | \xc3\xa9 | \xe9 | Latin small e with acute |
| í | 237 | u’\xed’ | \xc3\xad | \xed | Latin small i with acute |
| ñ | 241 | u’\xf1’ | \xc3\xb1 | \xf1 | Latin small n with tilde |
| ó | 243 | u’\xf3’ | \xc3\xb3 | \xf3 | Latin small o with acute |
| ú | 250 | u’\xfa’ | \xc3\xba | \xfa | Latin small u with acute |
| ü | 252 | u’\xfc’ | \xc3\xbc | \xfc | Latin small u with diaeresis |
¿Cómo trabaja python 2 con los distintos sistemas de codificación?
Vamos a entrar en materia: aunque podemos trabajar con distintas codificaciones, Python hace un procesamiento interno de los caracteres codificándolo con Unicode y luego convierte la salida a otros formatos, lo más habitual a utf-8. Por lo tanto el flujo de trabajo que realiza python en el tratamiento de caracteres es el siguiente:
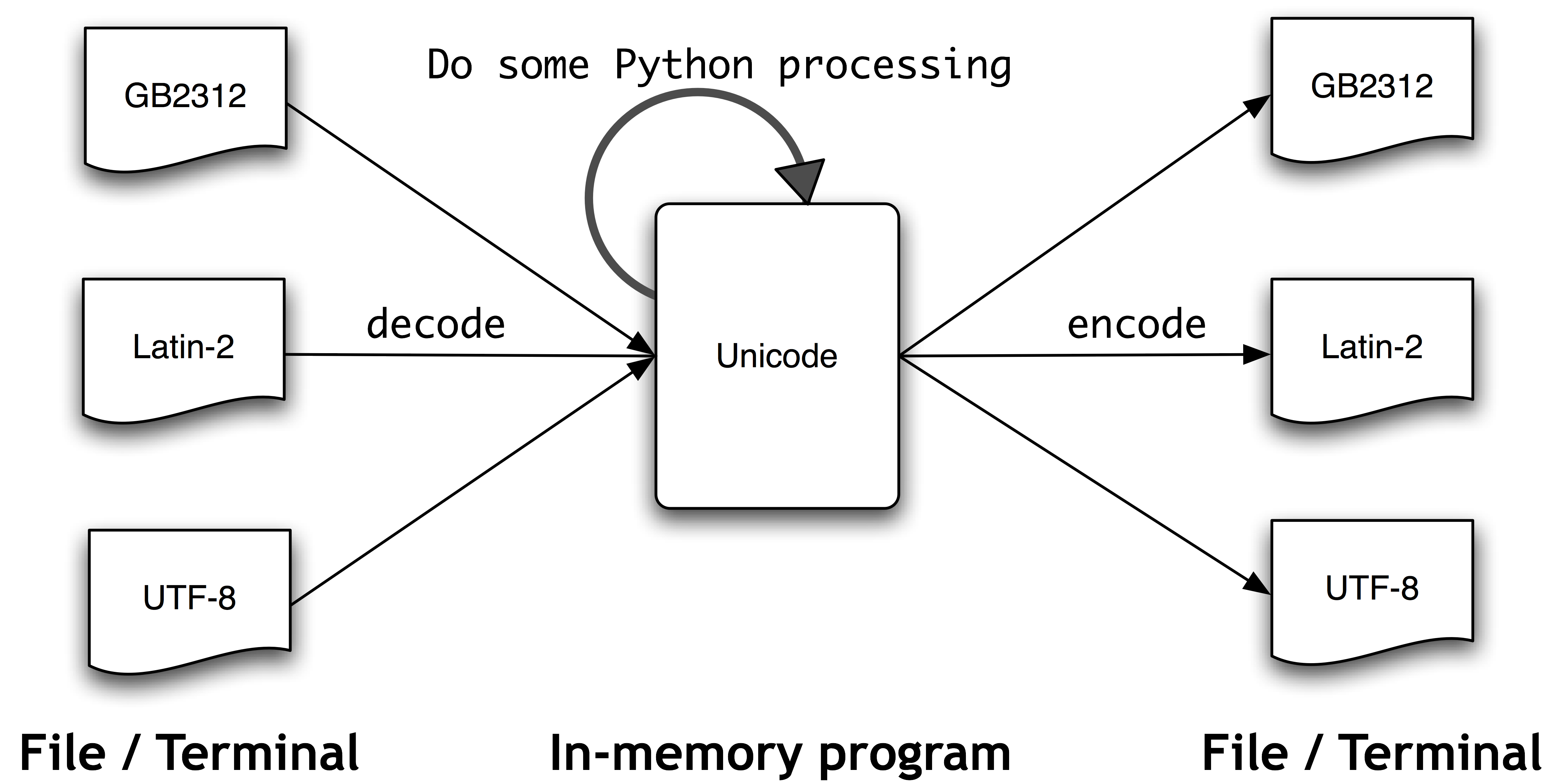
Es decir, la cadena se decodifica a Unicode, se hace el tratamiento interno necesario, y posterior se codifica a la codificación que necesitemos. Veamos algunos ejemplos:
1) Cuando creamos una cadena de caracteres (type str) por defecto la codificación es utf-8
>>> cad="josé"
>>> type (cad)
<type 'str'>Si comprobamos lo que se ha guardado realmente:
>>> cad
'jos\xc3\xa9'Por lo tanto si vemos que longitud tiene la cadena:
>>> print len(cad)
5Como veíamos en la tabla anterior el carácter é se representa en utf-8 con dos caracteres: \xc3\xa9. Si enviamos la cadena a la salida estándar, python es capaz de mostrarla de forma adecuada:
>>> print cad
joséY podemos, de esta manera imprimir el carácter é, de la siguiente forma:
>>> print '\xc3\xa9'
é2) Vamos a crear una cadena codificada con Unicode
>>> cad_uni = u'josé'
>>> type (cad_uni)
<type 'unicode'>Hemos utilizado el carácter u delante de la cadena para indicar la codificación unicode. Además la variable creada no es de tipo str, es de tipo unicode. Vemos realmente lo que tiene guardada la cadena:
>>> cad_uni
u'jos\xe9'En este caso, el carácter é se codifica con un sólo carácter /xe9. Podemos comprobar que en este caso la función len funciona de forma adecuada y que python también es capaz de representar de forma adecuada la cadena con print:
>>> len (cad_uni)
4
>>> print cad_uni
joséY por último si queremos imprimir el carácter é en unicode:
>>> print u'\xe9'
é3) Comparación de cadenas de caracteres con distintas codificaciones
Si tenemos dos cadenas con codificación distintas, aunque hayamos guardado el mismo valor, no son iguales:
>>> cad == cad_uni
__main__:1: UnicodeWarning: Unicode equal comparison failed to convert both arguments to Unicode - interpreting them as being unequal
FalsePor lo tanto tenemos que convertir una de las cadenas al otro código.
-
O convertimos de unicode a utf8 (codificamos):
>>> cad==cad_uni.encode("utf8") True -
O convertimos de utf8 a unicode (descodificamos):
>>> cad.decode("utf8")==cad_uni True
Otra forma de descodificar es utilizar la función unicode():
>>> unicode(cad,"utf8")==cad_uni
True4) Podemos intentar codificar una cadena unicode a un código ascii
En este caso si tenemos algún carácter que no esté codificado en la tabla ascii (128 caracteres), nos dará un error:
>>> cad_uni.encode("ascii")
Traceback (most recent call last):
File "<stdin>", line 1, in <module>
UnicodeEncodeError: 'ascii' codec can't encode character u'\xe9' in position 3: ordinal not in range(128)Podemos usar otras dos modalidades, ignorar el error:
>>> cad_uni.encode("ascii",errors='ignore')
'jos'O reemplazar el carácter que no corresponde al código ascii con el carácter “reemplazo” de unicode (U+FFFFD).
>>> cad_uni.encode("ascii",errors='replace')
'jos?'5) ¿Qué métodos tiene la clase unicode?
Tiene los mismos que la clase str, más dos nuEvos métodos: isdecimal() y isnumeric().
cad_uni.capitalize cad_uni.islower cad_uni.rpartition
cad_uni.center cad_uni.isnumeric cad_uni.rsplit
cad_uni.count cad_uni.isspace cad_uni.rstrip
cad_uni.decode cad_uni.istitle cad_uni.split
cad_uni.encode cad_uni.isupper cad_uni.splitlines
cad_uni.endswith cad_uni.join cad_uni.startswith
cad_uni.expandtabs cad_uni.ljust cad_uni.strip
cad_uni.find cad_uni.lower cad_uni.swapcase
cad_uni.format cad_uni.lstrip cad_uni.title
cad_uni.index cad_uni.partition cad_uni.translate
cad_uni.isalnum cad_uni.replace cad_uni.upper
cad_uni.isalpha cad_uni.rfind cad_uni.zfill
cad_uni.isdecimal cad_uni.rindex
cad_uni.isdigit cad_uni.rjustVeamos que ocurre con el método isnumeric():
>>> cad.isnumeric()
Traceback (most recent call last):
File "<stdin>", line 1, in <module>
AttributeError: 'str' object has no attribute 'isnumeric'
>>> cad_uni.isnumeric()
FalseLas cadenas de tipo str no tienen dicho método, mientras las unicode si.
6) Las funciones ord() y unichar()
Al igual que podemos utilizar la función chr() para obtener el caracter correspondiente a un código ascii.
>>> print chr(97)
aPodemos usar la función unichar() para mostrar un carácter a partir de un código unicode. La función ord() nos devuelve el código unicode a partir de un caracter.
>>> cad_uni=u'ñ'
>>> ord(cad_uni)
241
>>> unichr(241)
u'\xf1'
>>> print unichr(241)
ñConclusión
En esta entrada hemos abordado cómo trabaja python2 con las distintas codificaciones de caracteres. Lo he escrito pensando en mis alumnos del módulo de “Lenguaje de marcas”. Si hay que recordar que en python3 la clase string está codificada con Unicode por lo que el tratamiento de la codificación cambia radicalmente. Por lo tanto en una próxima entrada tratare la codificación de caracteres en python3.
hola jose,
estoy pegandome con las codificaciones tras hacer un requests en python3, no se si funcionaran igual que en python 2 (que usas en tus ejemplos):
Saludos
Hola Pablo
En python3 es distinto, porque la codificación por defecto en python3 la clase string está codificada con Unicode.
Para más información: https://docs.python.org/es/3/howto/unicode.html
Un saludo