Trabajar con ficheros xml desde python (1ª parte)

En este artículo voy a hacer una introducción al uso de la librería lxml de python que nos permite trabajar con ficheros xml. Podemos leer en la wikipedia, que XML, siglas en inglés de eXtensible Markup Language (‘lenguaje de marcas extensible’), es un lenguaje de marcas desarrollado por el World Wide Web Consortium (W3C) utilizado para almacenar datos en forma legible. Deriva del lenguaje SGML y permite definir la gramática de lenguajes específicos (de la misma manera que HTML es a su vez un lenguaje definido por SGML) para estructurar documentos grandes.
¿Cómo representa lxml el lenguaje XML?
Pongamos un ejemplo de fichero XML que representa la información de los libros vendidos en una librería:
<?xml version="1.0" encoding="utf-8"?>
<bookstore>
<book category="COOKING">
<title lang="en">Everyday Italian</title>
<author>Giada De Laurentiis</author>
<year>2005</year>
<price>30.00</price>
</book>
<book category="CHILDREN">
<title lang="en">Harry Potter</title>
<author>J K. Rowling</author>
<year>2005</year>
<price>29.99</price>
</book>
</bookstore>Cuando leemos el fichero xml anterior con la librería lxml, se crea una estructura de árbol (clase ElementTree), formado por objetos Element, que corresponden a cada elemento definido. Podríamos ver el esquema de la estructura que se crea en el siguiente gráfico:
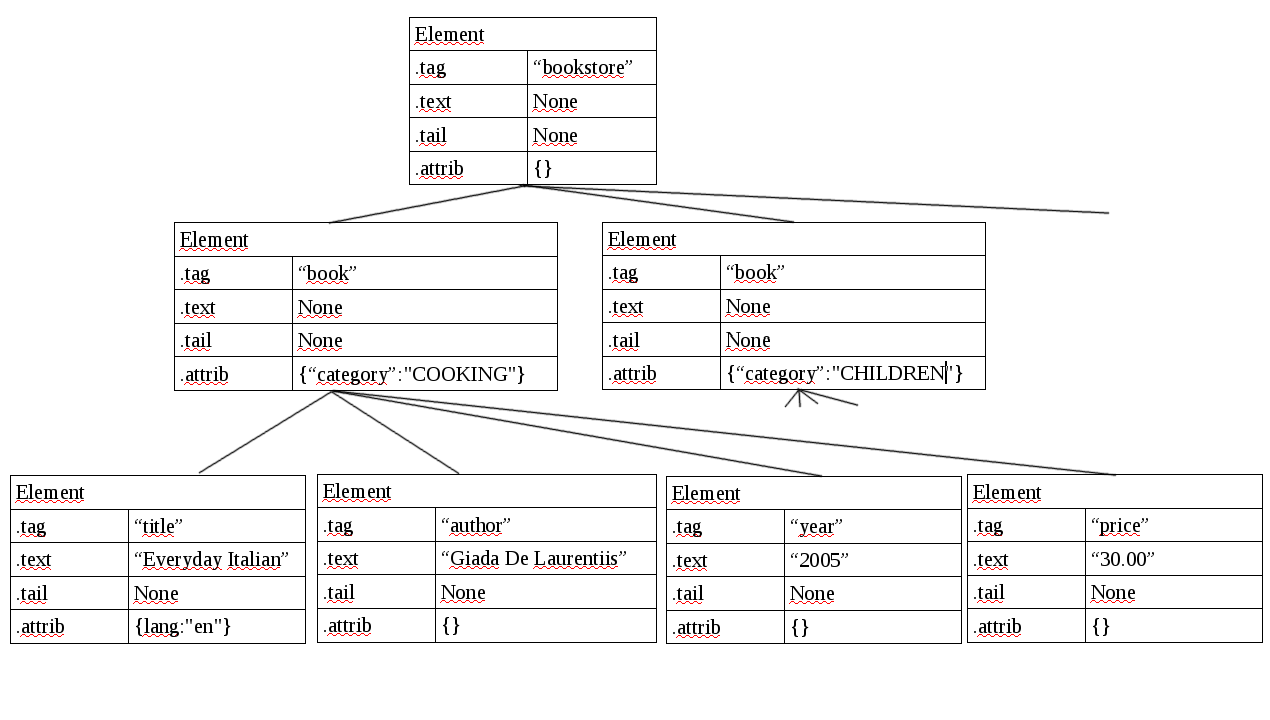
Cada objeto Element tiene cuatro atributos:
- Tag: el nombre de la etiqueta.
- Text: El texto guardado dentro de la etiqueta. Este atributo es
Nonesi la etiqueta está vacía. - Tail: El texto de un elemento, que está a continuación de otro elemento.
- Attrib: Un diccionario python que contiene los nombres y valores de los atributos del elemento.
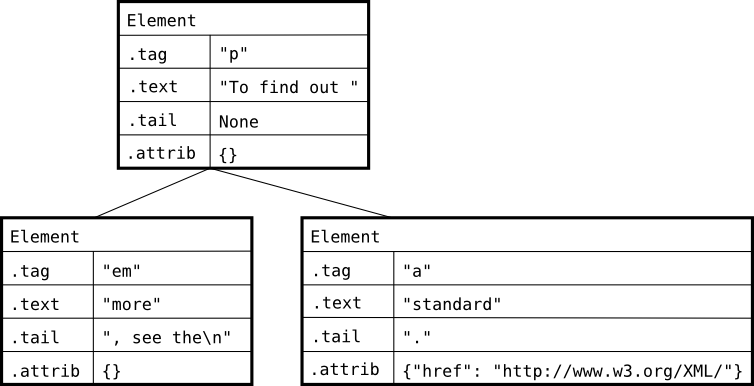
Para entender el contenido del atributo Tail, podemos ver un ejemplo de HTML que encontramos en la siguiente página:
<p>To find out <em>more</em>, see the <a href="http://www.w3.org/XML">standard</a>.</p>En este caso el esquema generado sería el siguiente:
¿Cómo podemos leer y escribir documentos XML?
Lo primero que tenemos que hacer es comprobar si tenemos instalado el paquete python-lxml, si no es así lo instalamos:
apt-get install python-lxmlPara leer un documento XML tenemos que usar el método parse del objeto etree, podemos indicar un fichero que tengamos en el disco duro, o una URL donde se encuentre el fichero:
from lxml import etree
doc = etree.parse('books.xml')Una vez que tenemos creado la estructura ElementTree, que en nuestro caso se guarda en el objeto doc, podemos serializar la salida utilizando la siguiente instrucción:
print etree.tostring(doc,pretty_print=True ,xml_declaration=True, encoding="utf-8")El objeto Element
El árbol que se ha generado al leer el documento XML se guarda en un objeto de la clase ElementTree, que en nuestro ejemplo se llama doc. Cada uno de los elementos que forman la estructura se van a guardar en objeto de la clase Element. Por ejemplo podemos obtener el elemento raíz utilizando el siguiente método de la clase ElementTree:
raiz=doc.getroot()
print raiz.tagEl objeto raíz es de clase Element y tiene los atributos que vimos anteriormente (tag,text,tail,attrib), en el ejemplo anterior se muestra el nombre de la etiqueta (tag) que en nuestro ejemplo sería “bookstore”.
Además el objeto raíz, contiene una lista que representa los distintos elementos hijos, del tal manera que podemos obtener cuántos elementos hijos tiene utilizando la función len:
print len(raiz)En este caso obtenemos el número de elementos books que tiene nuestro elemento raíz “bookstore”.
Si queremos obtener el elemento que representa el primer libro:
libro=raiz[0]
print libro.tag
print libro[0].textEl objeto libro es de la clase Element, con la segunda instrucción hemos mostrado la etiqueta del elemento, y con la tercera hemos mostrado el texto del primer elemento hijo, que en nuestro caso es el elemento title, con lo que mostramos el título del libro.
Los atributos son un diccionario en python, por lo tanto para mostrar la información del atributo del elemento libro podemos recorrerlo de la siguiente manera:
for attr,value in libro.items():
print attr,valuePara mostrar el contenido de un atributo del elemento libro:
print libro.get("category")También podemos utilizar el atributo attrib que devuelve el diccionario, de esta mnaera:
print libro.attrib["category"]Buscando información en el documento XML
Tenemos a nuestra disposición distintos métodos para realizar búsquedas:
-
find(): Devuelve el primer
Elementcuya etiqueta corresponda al criterio de búsqueda que le proporcionamos. Podemos utilizarlo a partir de un objetoElementTree, o a partir de un elementoElement, por ejemplo si queremos mostrar el precio del primer libro, podemos ponerlo de alguna de las siguientes tres maneras:precio=doc.find("book/price") precio=raiz.find("book/price") precio=libro.find("price")Señalar que en la tercera instrucción la búsqueda se hace desde el elemento “book”.
-
findall(): Devuelve una lista de objetos
Elementque coinciden con el criterio de búsqueda. Podemos también utilizarlo a partir de un objetoElementTree, o a partir de un elementoElement. Por ejemplo si queremos obtener todos los libros y mostrar sus precios:libros=doc.findall("book") print libros[0].find("price").text print libros[1].find("price").text -
findtext(): Devuelve el contenido del atributo
textdel primer elemento que coincida con el criterio de búsqueda. Por ejemplo para obtener el año de edición del primer libro, lo podemos hacer de alguna de las siguientes maneras:print doc.findtext("book/year") print raiz.findtext("book/year") print libro.findtext("year") -
iterancestors(): Nos permite iterar entre los elementos ascendentes de un elemento dado, por ejemplo si queremos conocer el padre, o el abuelo de un elemento. Por ejemplo para obtener el elemento padre de un libro:
for padre in libro.iterancestors(): print padre.tag
Tenemos a nuestra disposición muchos más métodos que podemos usar y que puedes aprender en las páginas que he utilizado como referencia para escribir este artículo:
Excelente desarrollo, mas claro imposible... se agradece de corazon!!!