Almacenamiento de objetos con Amazon Web Service S3

En este artículo voy a hacer una introducción a Amazon Web Service S3(Simple Storage Service), que nos ofrece un servicio de almacenamiento masivo de objetos. AWS S3 ofrece un almacén de objetos distribuido y altamente escalable. Se utiliza para almacenar grandes cantidades de datos de forma segura y económica. El almacenamiento de objetos es ideal para almacenar grandes ficheros multimedia o archivos grandes como copias de seguridad. Otra utilidad que nos ofrece es el almacenamiento de los datos estáticos de nuestra página web, que es lo que vamos a estudiar en esta entrada.
Conceptos sobre AWS S3
Para la organización de nuestros archivos, tenemos que conocer los siguientes conceptos:
- buckets: son algo parecido a un directorio o carpeta de nuestro sistema operativo, donde colocaremos nuestros archivos. Los nombres de los buckets están compartidos entre toda la red de Amazon S3, por lo que si creamos un bucket, nadie más podrá usar ese nombre para un nuevo bucket.
- objects: son las entidades de datos en sí, es decir, nuestros archivos. Un object almacena tanto los datos como los metadatos necesarios para S3, y pueden ocupar entre 1 byte y 5 Gigabytes.
- keys: son una clave única dentro de un bucket que identifica a los objects de cada bucket. Un object se identifica de manera unívoca dentro de todo S3 mediante su bucket+key.
- ACL: Podemos indicar el control de acceso a nuestro objetos, podremos dar capacidad de “Lectura”, “Escritura” o “Control Total”.
Más características de AWS S3
- Uso de una API sencilla para la comunicación de nuestras aplicaciones con S3. Estas peticiones HTTP nos permitirán la gestión de los objetos, buckets, … En definitiva, todas las acciones necesarias para administrar nuestro S3. Toda la información en cuanto accesos y códigos de ejemplo se pueden encontrar en la documentación oficial.
- Para la descargas de los objetos tenemos dos alternativas: si eres el propietario del objeto puedes hacer una llamada a la API para la descarga, sino, si hemos configurado el objeto con una ACL de lectura, podemos utilizar una URL para accder a él. Cada archivo en S3 posee una URL única, lo que nos facilitará mucho el poner a disposición de nuestros clientes todos los datos que almacenemos.
- El servicio se paga por distintos conceptos: almacenamiento, transferencia, peticiones GET o PUT,… pero hay que tener en cuenta, siendo un servicio de Cloud Computing, que el pago se realiza por uso. La tarifas son baratas y las puedes consultar en la siguiente página.
Instalación y configuración del cliente de línea de comando AWS
La forma más cómoda de instalar el cliente de línea de comando en un sistema operativo GNU/Linux Debian es utilizando la utilidad pip, para ello ejecutamos los siguientes comandos:
# apt-get install python-pip
# pip install awscliPodemos comprobar la versión que hemos instalado:
# aws --version
aws-cli/1.10.1 Python/2.7.9 Linux/3.16.0-4-amd64 botocore/1.3.23La CLI de AWS nos permite gestionar todo lo relacionado con Amazon Web Services sin necesidad de acceder a la consola de administración web. Para poder utilizarlo tenemos que configurar el cliente para autentificarnos, especificando nuestro AWS Access Key ID y AWS Secret Access Key que hemos creado en la consola web:
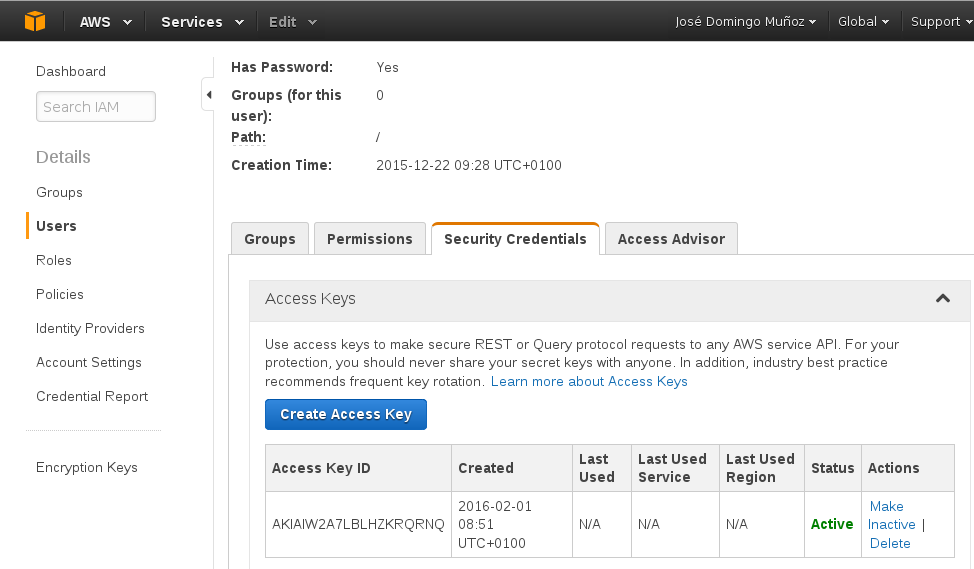
Para realizar la configuración:
$ aws configure
AWS Access Key ID [None]: AKIAIW2A7LBLHZKRQRNQ
AWS Secret Access Key [None]: **********************************
Default region name [None]:
Default output format [None]:Para trabajar con AWS S3 no hace falta indicar la región que vamos a usar, y el formato de salida tampoco lo hemos indicado.
Uso del cliente de línea de comando AWS
Para empezar vamos a comprobar si tenemos permiso para acceder a los recursos de nuestra cuenta en AWS S3, por ejemplo intentando visualizar la lista de buckets que tenemos:
$ aws s3 lsA client error (AccessDenied) occurred when calling the ListBuckets operation: Access Denied
Como podemos comprobar tenemos que añadir una política de acceso para permitir el acceso a S3, para ello desde la consola web, nos vamos a la pestaña Permissions y añadimos una nueva política en la opción Attach Policy y escogemos: AmazonS3FullAccess:
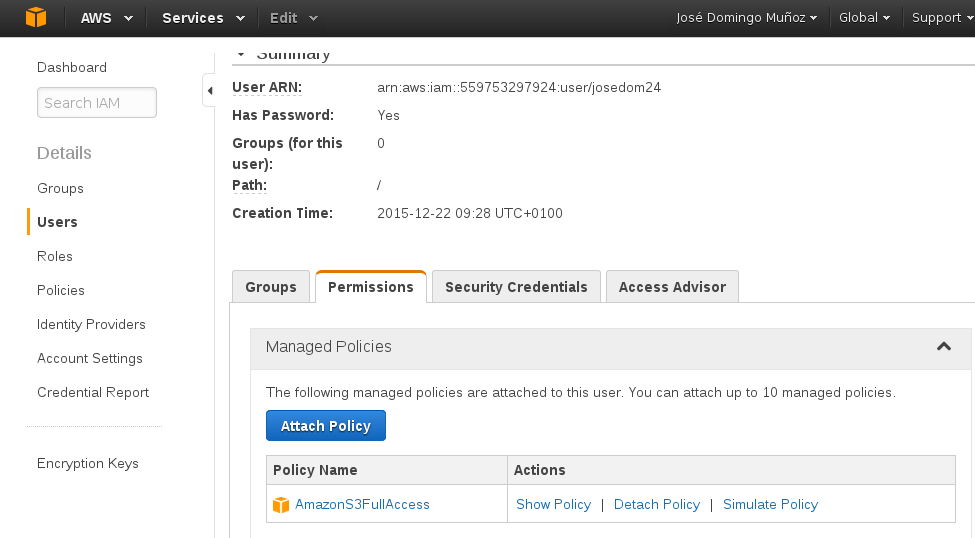
Y podemos comenzar a trabajar:
Listar, crear y eliminar buckets
Los “buckets” o “cubos” es el contenedor S3 donde se almacenarán los datos. Para crear uno, debemos elegir un nombre (tiene que ser válido a nivel de DNS y único). Para crear un nuevo buckets:
$ aws s3 mb s3://storage_pledin1
make_bucket: s3://storage_pledin1/Para listar los buckets que tenemos creado:
$ aws s3 ls
2016-02-01 08:22:25 storage_pledin1Y si quisiéramos borrarlo:
$ aws s3 rb s3://storage_pledin1
remove_bucket: s3://storage_pledin1/Subir, descargar y eliminar objetos
Con la CLI de aws se incluyen los comandos cp, ls, mv, rm y sync. Todos ellos funcionan igual que en las shell de Linux. Sync es un añadido que permite sincronizar directorios completos. Vamos a ver unos ejemplos:
Copiar de local a remoto:
$ aws s3 cp BabyTux.png s3://storage_pledin1
upload: ./BabyTux.png to s3://storage_pledin1/BabyTux.pngListar el contenido de un bucket:
$ aws s3 ls s3://storage_pledin1
2016-02-01 08:29:49 147061 BabyTux.pngMover/renombrar un archivo remoto:
$ aws s3 mv s3://storage_pledin1/BabyTux.png s3://storage_pledin1/tux.png
move: s3://storage_pledin1/BabyTux.png to s3://storage_pledin1/tux.pngCopiar archivos remotos:
$ aws s3 cp s3://storage_pledin1/tux.png s3://storage_pledin1/tux2.png
copy: s3://storage_pledin1/tux.png to s3://storage_pledin1/tux2.png
$ aws s3 ls s3://storage_pledin1
2016-02-01 08:33:07 147061 tux.png
2016-02-01 08:34:01 147061 tux2.pngLa parte de sincronización también es fácil de utilizar usando el comando sync, indicamos el origen y el destino y sincronizará todos los archivos y directorios que contenga:
Sincronizar los ficheros de un directorio local a remoto:
$ aws s3 sync prueba/ s3://storage_pledin1/prueba
upload: prueba/fich2.txt to s3://storage_pledin1/prueba/fich2.txt
upload: prueba/fich1.txt to s3://storage_pledin1/prueba/fich1.txt
upload: prueba/fich3.txt to s3://storage_pledin1/prueba/fich3.txt
$ aws s3 ls s3://storage_pledin1/prueba/
2016-02-01 08:50:45 0 fich1.txt
2016-02-01 08:50:45 0 fich2.txt
2016-02-01 08:50:45 0 fich3.txtAcceso a los objetos
Amazon S3 Access Control Lists (ACLs) nos permite manejar el acceso a los objetos y buckets de nuestro proyecto. Cuando se crea un objeto o un bucket se define una ACL que otorga control total (full control) al propietario del recurso. Podemos otorgar distintos permisos a usuarios y grupos de AWS. Para saber más sobre permisos en S3 puedes consultar el documento: Access Control List (ACL) Overview
En esta entrada nos vamos a conformar en mostrar una ACL que nos permita hacer público un objeto y de esta manera poder acceder a él. Para acceder a un recurso en S3 podemos hacerlo de dos maneras:
- Si somos un usuario o pertenecemos a un grupo de AWS y el propietario del recurso nos ha dado permiso para acceder o modificar el recurso.
- O, sin necesidad de estar autentificados, que el propietario del recurso haya dado permiso de lectura al recurso para todo el mundo, es decir lo haya hecho público. Esta opción es la que vamos a mostrar a continuación.
Anteriormente hemos subido una imagen (tux.png) como objeto a nuestro bucket, como hemos dicho cuando se crea el objeto, por defecto se declara como privado. Si accedemos a dicho recurso utilizando la siguiente URL:
https://s3.amazonaws.com/storage_pledin1/tux.pngVemos como el control de acceso no nos deja acceder al recurso:
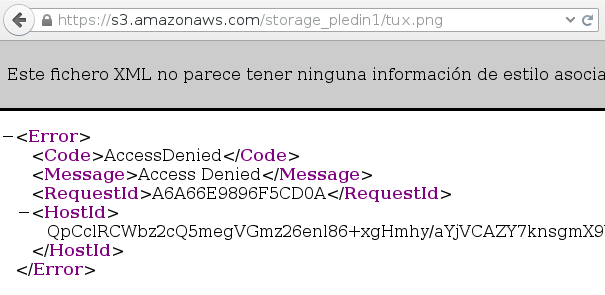
Cuando copiamos el objeto al bucket podemos indicar la ACL para hacer le objeto público, de la siguiente manera:
aws s3 cp tux.png s3://storage_pledin1 --acl public-read-writeDe tal manera que ahora podemos acceder al recurso:
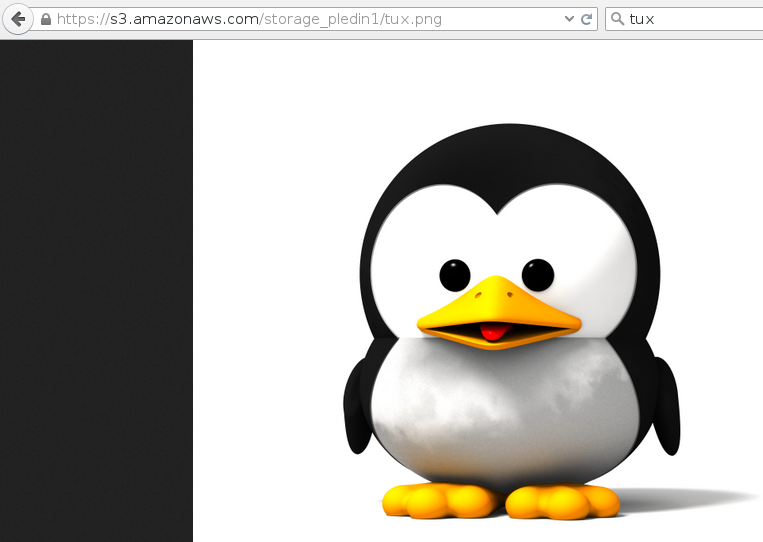
Conclusiones
El uso del almacenamiento de objetos no es algo nuevo en la informática, pero si ha tenido una gran importancia en los últimos tiempo con el uso masivo que se hace de los entorno IaaS de Cloud Computing. En este artículo he intentado hacer una pequeña introducción a la solución de almacenamiento de objetos que nos ofrece AWS, aunque los conceptos son muy similares y totalmente transportables a otras soluciones, como puede ser OpenStack y su componente de almacenamiento de objetos Swift.